In the previous post I spoke briefly about motivations for implementing self-organizing maps in F# using GPU with CUDA. I have finally been able to outperform a single threaded C++ implementation by a factor of about 1.5. This is quite modest, but on the other hand rather impressive since we started out by being 60 times slower. At this point I am bidding farewell to F# and switching to C++. It will be interesting to see how this works out, but here are my initial algorithms.
So, we are parallelizing the following:
member this.GetBMU (node : Node) =
let min = ref Double.MaxValue
let minI = ref -1
let minJ = ref -1
this.somMap |> Array2D.iteri (fun i j e ->
let dist = getDistance e node this.Metric
if dist < !min then min := dist; minI := i; minJ := j)
!minI, !minJ
Here somMap is just a two-dimensional array of Node-s. And a Node is simply an array of float’s (double’s in C#), of the size equal to dimensionality of our space.
The code for getDistance is also simple:
let getDistanceEuclidian (x : Node) (y : Node) =
Math.Sqrt([0..x.Dimension - 1] |> Seq.fold(fun sq i -> sq + (x.[i] - y.[i]) ** 2.) 0.)
let getDistance (x : Node) (y : Node) metric =
if x.Dimension <> y.Dimension then failwith "Dimensions must match"
else
match metric with
| Euclidian ->
getDistanceEuclidian x y
| Taxicab ->
getDistanceTaxicab x y
In my parallel version I am only using Euclidian distance for simplicity.
Parallel Algorithms
As I have mentioned above, Alea.cuBase (my F#-to-CUDA framework) does not support multidimensional arrays (as well as shared memory or calling a kernel from a kernel), so this is the price I had to pay for sticking to my favorite language. Given these constraints, here is what I came up with:
Node-by-node
The very first idea (that proved also the very best) is quite intuitive. To find BMUs for the entire set of nodes, just take each individual node, find its BMU in parallel, repeat.
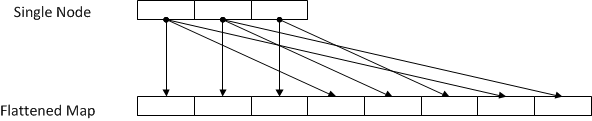
The map is first flattened into a single dimension, where if the cell coordinates were (i, j, k), they are mapped to (i * j * k + j * k + k). All distance sub-calculations can be performed in one shot, and then one thread finishes them up. By “sub-calculation” I mean computing (node(i) – map(j)) ** 2. These are then added up to the distance squared (I don’t calculate sqrt, since I don’t need it to find the minimum).
So, here is the implementation:
let pDistances =
cuda {
let! kernel =
<@ fun nodeLen len
(node : DevicePtr<float>)
(map : DevicePtr<float>)
(distances : DevicePtr<float>)
(minDist : DevicePtr<float>)
(minIndex : DevicePtr<int>)
->
// index into the original map, assuming
// a node is a single entity
let mapI = blockIdx.x * blockDim.x
// actual position of the node component in the map
let i = mapI + threadIdx.x
if i < len then
// index into the node
let j = threadIdx.x % nodeLen
distances.[i] <- (map.[i] - node.[j]) * (map.[i] - node.[j])
if threadIdx.x = 0 then
__syncthreads()
let mutable thread = 0
minIndex.[blockIdx.x] <- -1
// find the minimum among threads
while mapI + thread < len && thread < blockDim.x do
let k = mapI + thread
let mutable sum = 0.
for j = 0 to nodeLen - 1 do
sum <- sum + distances.[k + j]
if minDist.[blockIdx.x] > sum || minIndex.[blockIdx.x] < 0 then
minDist.[blockIdx.x] <- sum
minIndex.[blockIdx.x] <- k / nodeLen
thread <- thread + nodeLen
@> |> defineKernelFunc
let diagnose (stats:KernelExecutionStats) =
printfn "gpu timing: %10.3f ms %6.2f%% threads(%d) reg(%d) smem(%d)"
stats.TimeSpan
(stats.Occupancy * 100.0)
stats.LaunchParam.BlockDim.Size
stats.Kernel.NumRegs
stats.Kernel.StaticSharedMemBytes
return PFunc(fun (m:Module) (nodes : float [] list) (map : float []) ->
let kernel = kernel.Apply m
let nodeLen = nodes.[0].Length
let chunk = map.Length
let nt = (256 / nodeLen) * nodeLen // number of threads divisible by nodeLen
let nBlocks = (chunk + nt - 1)/ nt //map.Length is a multiple of nodeLen by construction
use dMap = m.Worker.Malloc(map)
use dDist = m.Worker.Malloc<float>(map.Length)
use dMinIndices = m.Worker.Malloc<int>(nBlocks * nodes.Length)
use dMinDists = m.Worker.Malloc<float>(nBlocks * nodes.Length)
use dNodes = m.Worker.Malloc(nodes.SelectMany(fun n -> n :> float seq).ToArray())
let lp = LaunchParam(nBlocks, nt) //|> Engine.setDiagnoser diagnose
nodes |> List.iteri (fun i node ->
kernel.Launch lp nodeLen chunk (dNodes.Ptr + i * nodeLen) dMap.Ptr dDist.Ptr (dMinDists.Ptr + i * nBlocks) (dMinIndices.Ptr + i * nBlocks))
let minDists = dMinDists.ToHost()
let indices = dMinIndices.ToHost()
let mins = (Array.zeroCreate nodes.Length)
for i = 0 to nodes.Length - 1 do
let baseI = i * nBlocks
let mutable min = minDists.[baseI]
mins.[i] <- indices.[baseI]
for j = 1 to nBlocks - 1 do
if minDists.[baseI + j] < min then
min <-minDists.[baseI + j]
mins.[i] <- indices.[baseI + j]
mins
)
}
To get as much parallelism as possible, I start with 256 threads per block (maximum on Kepler is 1024, but 256 gives the best performance). Since each block of threads is going to compute as many distances as possible, I try to allocate the maximum number of threads divisible by node dimensionality. In my case: 256 / 12 * 256 = 252. Pretty good, we get almost an optimal number of threads per block.
The number of blocks are computed from the length of the map. I want to split this in an optimal way since each block is scheduled on one SP, and I have 192 of those I don’t want them to idle. The algorithm leans towards parallelizing calculations relative to the map (see picture above, I want all those “arrows” to be executed in parallel), so the number of blocks will be (somArray.length + nt – 1) / nt (nt is the number of threads – 252, somArray.length is 200 * 200 * 12 = 480000, the formula above takes into account the fact that this number may not be a multiple of 252, in which case we will need one more incomplete block). My block size is 1905 – pretty good, CUDA devs recommend that to be at least twice the number of multiprocessors. It is necessary to hide latency, which is killer in this development paradigm (you need to rely on your PCI slot to transfer data).
One weird thing here is that I have to allocate a relatively large dDist arrray. This is where temporary values of (map(i) – node(j))**2 go. In reality (if I were writing in C++) I would not do that. I would just use the super-fast shared memory for this throw-away array. I could not get that to work with Alea, although the documentation says it is supported.
Another thing: the call to __syncthreads() is issued under a conditional statement. This, in general, is a horrible idea, because in the SIMT (single instruction multiple threads), threads march “in sync” so to speak, instruction by instruction. Thus, doing what I have done may lead to things hanging as some threads may take different branches and other threads will wait forever. Here, however, we are good, because the only way to go if the condition evaluates to false is to simply quit.
The kernel is called in a loop. One call for each node: 10000 passes (vs 10000 * 40000) in the sequential case. I also make sure that all of my memory is allocated once and everything I need is copied there. Not doing that leads to disastrous consequences, since all you would have in that case is pure latency.
The code is self-explanatory. Once everyone has computed their part of the distance, these parts are assembled by the 0-th thread of the block. That thread is responsible for calculating the final square of the distance, comparing the result of what we already have in the minDist array for this map node and storing that result.
Node-by-node optimized
And here lies the mistake that makes this algorithm lose out on performance: there is no need to delegate this work to the 0-th thread (looping over all 252 threads of the block). It is enough to delegate that to each “threadIdx.x % nodeLen = 0″‘s thread of the block, so now 21 threads do this work in parallel, each for only 12 threads. Algorithm re-written this way outperforms everything else I could come up with.
Here is the re-write of the kernel function:
let! kernel =
<@ fun nodeLen len
(node : DevicePtr<float>)
(map : DevicePtr<float>)
(distances : DevicePtr<float>)
(minDist : DevicePtr<float>)
(minIndex : DevicePtr<int>)
->
// index into the original map, assuming
// a node is a single entity
let mapI = blockIdx.x * blockDim.x
// actual position of the node component in the map
let i = mapI + threadIdx.x
if i < len then
// index into the node
let j = threadIdx.x % nodeLen
distances.[i] <- (map.[i] - node.[j]) * (map.[i] - node.[j])
__syncthreads()
if threadIdx.x % nodeLen = 0 then
minIndex.[blockIdx.x] <- -1
// find the minimum among threads
let k = mapI + threadIdx.x
let mutable sum = 0.
for j = k to k + nodeLen - 1 do
sum <- sum + distances.[j]
if minDist.[blockIdx.x] > sum || minIndex.[blockIdx.x] < 0 then
minDist.[blockIdx.x] <- sum
minIndex.[blockIdx.x] <- k / nodeLen
@> |> defineKernelFunc
This kernel function only stores “winning” (minimal) distances within each section of the map. Now they need to be reduced to one value per node. There are 1905 blocks and 10000 nodes. 10000 minimum values are computed in one pass over the 1905 * 10000-length array of accumulated minimal distances:
let minDists = dMinDists.ToHost()
let indices = dMinIndices.ToHost()
let mins = (Array.zeroCreate nodes.Length)
for i = 0 to nodes.Length - 1 do
let baseI = i * nBlocks
let mutable min = minDists.[baseI]
mins.[i] <- indices.[baseI]
for j = 1 to nBlocks - 1 do
if minDists.[baseI + j] < min then
min <-minDists.[baseI + j]
mins.[i] <- indices.[baseI + j]
mins
And we are done. The improved version beats all the rest of my algorithms. Since all of these performance improvements looked so “juicy”, I decided it was high time to abandon managed code and go back to the C++ world. Especially since writing C++ code is not going to be so different: no annoying loops to write, just express it linearly and reap the massively parallel goodness.

One thought on “Computing Self-Organizing Maps in a Massively Parallel Way with CUDA. Part 2: Algorithms”