Code
The complete source: here
Intro
Starting to play with graph algorithms on the GPU (who wants to wait for nvGraph from NVIDIA, right?) As one of the precursor problems – sorting large arrays of non-negative integers came up. Radix sort is a simple effective algorithm quite suitable for GPU implementation.
Least Significant Digit Radix Sort
The idea is simple. We take a set A of fixed size elements with lexicographical ordering defined. We represent each element in a numeric system of a given radix (e.g., 2). We then scan each element from right to left and group the elements based on the digit within the current scan window, preserving the original order of the elements. The algorithm is described here in more detail.
Here is a the pseudocode for radix = 2 (easy to extend for any radix):
k = sizeof(int)
n = array.length
for i = 0 to k
all_0s = []
all_1s = []
for j = 0 to n
if bit(i, array[j]) == 0
then all_0s.add(array[j])
else all_1s.add(array[j])
array = all_0s + all_1s
GPU Implementation
This is a poster problem for the “split” GPU primitive. Split is what <code>GroupBy</code> is in LINQ (or <code>GROUP BY</code> in TSQL) where a sequence of entries are split (grouped) into a number of categories. The code above applies split k times to an array of length n, each time the categories are are “0” and “1”, and splitting/grouping are done based on the current digit of an entry.
The particular case of splitting into just two categories is easy to implement on the GPU. Chapter 39 of GPU Gems describes such implementation (search for “radix sort” on the page).
The algorithm described there shows how to implement the pseudocode above by computing the position of each member of the array in the new merged array (line 10 above) without an intermediary of accumulating lists. The new position of each member of the array is computed based on the exclusive scan where the value of scanned[i] = scanned[i – 1] + 1 when array[i-1] has 0 in the “current” position. (scanned[0] = 0). Thus, by the end of the scan, we know where in the new array the “1” category starts (it’s scanned[n – 1] + is0(array[n – 1]) – total length of the “0” category, and the new address of each member of the array is computed from the scan: for the “0” category – it is simply the value of scanned (each element of scanned is only increased when a 0 bit is encountered), and start_of_1 + (i – scanned[i]) for each member of the “1” category: its position in the original array minus the number of “0” category members up to this point, offset by the start of the “1” category.
The algorithm has two parts: sorting each block as described above and then merging the results. In our implementation we skip the second step, since Alea.CUDA DeviceScanModule does the merge for us (inefficiently so at each iteration, but makes for simpler, more intuitive code).
Coding with Alea.CUDA
The great thing about Alea.CUDA libray v2 is the Alea.CUDA.Unbound namespace that implements all kinds of scans (and reducers, since a reducer is just a scan that throws away almost all of its results).
let sort (arr : int []) =
let len = arr.Length
if len = 0 then [||]
else
let gridSize = divup arr.Length blockSize
let lp = LaunchParam(gridSize, blockSize)
// reducer to find the maximum number & get the number of iterations
// from it.
use reduceModule = new DeviceReduceModule<int>(target, <@ max @>)
use reducer = reduceModule.Create(len)
use scanModule = new DeviceScanModule<int>(target, <@ (+) @>)
use scanner = scanModule.Create(len)
use dArr = worker.Malloc(arr)
use dBits = worker.Malloc(len)
use numFalses = worker.Malloc(len)
use dArrTemp = worker.Malloc(len)
// Number of iterations = bit count of the maximum number
let numIter = reducer.Reduce(dArr.Ptr, len) |> getBitCount
let getArr i = if i &&& 1 = 0 then dArr else dArrTemp
let getOutArr i = getArr (i + 1)
for i = 0 to numIter - 1 do
// compute significant bits
worker.Launch <@ getNthSignificantReversedBit @> lp (getArr i).Ptr i len dBits.Ptr
// scan the bits to compute starting positions further down
scanner.ExclusiveScan(dBits.Ptr, numFalses.Ptr, 0, len)
// scatter
worker.Launch <@ scatter @> lp (getArr i).Ptr len numFalses.Ptr dBits.Ptr (getOutArr i).Ptr
(getOutArr (numIter - 1)).Gather()
let generateRandomData n =
if n <= 0 then failwith "n should be positive"
let seed = uint32 DateTime.Now.Second
// setup random number generator
use cudaRandom = (new XorShift7.CUDA.DefaultNormalRandomModuleF32(target)).Create(1, 1, seed) :> IRandom<float32>
use prngBuffer = cudaRandom.AllocCUDAStreamBuffer n
// create random numbers
cudaRandom.Fill(0, n, prngBuffer)
// transfer results from device to host
prngBuffer.Gather() |> Array.map (((*) (float32 n)) >> int >> (fun x -> if x = Int32.MinValue then Int32.MaxValue else abs x))
This is basically it. One small optimization - instead of looping 32 times (length of int in F#), we figure out the bit count the largest element and iterate fewer times.
Helper functions/kernels are straightforward enough:
let worker = Worker.Default
let target = GPUModuleTarget.Worker worker
let blockSize = 512
[<Kernel; ReflectedDefinition>]
let getNthSignificantReversedBit (arr : deviceptr<int>) (n : int) (len : int) (revBits : deviceptr<int>) =
let idx = blockIdx.x * blockDim.x + threadIdx.x
if idx < len then
revBits.[idx] <- ((arr.[idx] >>> n &&& 1) ^^^ 1)
[<Kernel; ReflectedDefinition>]
let scatter (arr : deviceptr<int>) (len: int) (falsesScan : deviceptr<int>) (revBits : deviceptr<int>) (out : deviceptr<int>) =
let idx = blockIdx.x * blockDim.x + threadIdx.x
if idx < len then
let totalFalses = falsesScan.[len - 1] + revBits.[len - 1]
// when the bit is equal to 1 - it will be offset by the scan value + totalFalses
// if it's equal to 0 - just the scan value contains the right address
let addr = if revBits.[idx] = 1 then falsesScan.[idx] else totalFalses + idx - falsesScan.[idx]
out.[addr] <- arr.[idx]
let getBitCount n =
let rec getNextPowerOfTwoRec n acc =
if n = 0 then acc
else getNextPowerOfTwoRec (n >>> 1) (acc + 1)
getNextPowerOfTwoRec n 0
Generating Data and Testing with FsCheck
I find FsCheck quite handy for quick testing and generating data with minimal setup in FSharp scripts:
let genNonNeg = Arb.generate<int> |> Gen.filter ((<=) 0)
type Marker =
static member arbNonNeg = genNonNeg |> Arb.fromGen
static member ``Sorting Correctly`` arr =
sort arr = Array.sort arr
Arb.registerByType(typeof<Marker>)
Check.QuickAll(typeof<Marker>)
Just a quick note: the first line may seem weird at first glance: looks like the filter condition is dropping non-positive numbers. But a more attentive second glance reveals that it is actually filtering out negative numbers (currying, prefix notation should help convince anyone in doubt).
Large sets test.
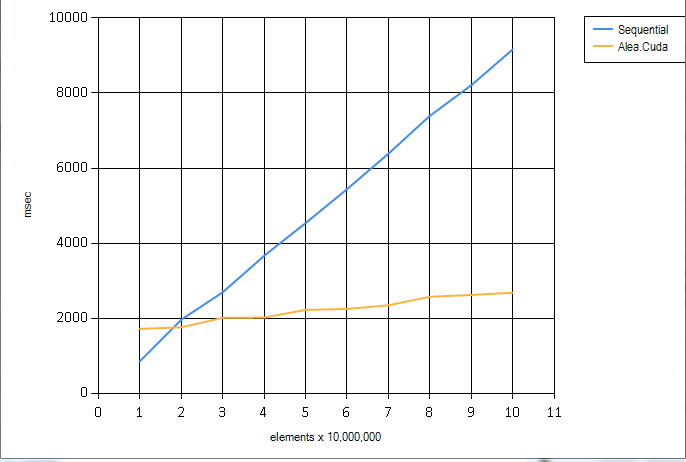
I have performance tested this on large datasets (10, 000, 000 - 300, 000, 000) integers, any more and I'm out of memory on my 6 Gb Titan GPU. The chart below goes up to 100,000,000.
I have generated data for these tests on the GPU as well, using Alea.CUDA random generators, since FsCheck generator above is awfully slow when it comes to large enough arrays.
The code comes almost verbatim from this blog post:
let generateRandomData n =
if n <= 0 then failwith "n should be positive"
let seed = uint32 DateTime.Now.Second
// setup random number generator
use cudaRandom = (new XorShift7.CUDA.DefaultNormalRandomModuleF32(target)).Create(1, 1, seed) :> IRandom<float32>
use prngBuffer = cudaRandom.AllocCUDAStreamBuffer n
// create random numbers
cudaRandom.Fill(0, n, prngBuffer)
// transfer results from device to host
prngBuffer.Gather() |> Array.map (((*) (float32 n)) >> int >> (fun x -> if x = Int32.MinValue then Int32.MaxValue else abs x))
except I'm converting the generated array to integers in the [0; n] range. Since my radix sort work complexity is O(k * n) (step complexity O(k)) where k = bitCount(max input) I figured this would give an adequate (kinda) comparison with the native F# Array.orderBy .
Optimization
It is clear from the above chart, that there is a lot of latency in our GPU implementation - the cost we incur for the coding nicety: by using DeviceScanModule and DeviceReduceModule we bracket the merges we would otherwise have to do by hand. Hence the first possible optimization: bite the bullet, do it right, with a single merge at the end of the process and perform a block-by-block sort with BlockScanModule

Thanks for wwriting