Continuing the Advent of Code theme from the previous post. Figured since this year is going to be my year of CUDA, this would be a good opportunity to take it for a ride. A good April 1st post, but why wait?
So, how can we make this even faster than the already fast imperative solution?
Naive Approach
The complete script for this is on GitHub.
The kernel computes one iteration of the look-and-say sequence. Every instance looks at a single group of repeating digits and outputs the result into an array. The new array is twice the size of the original one (representing a previous member of the sequence), every digit or the first digit of a group will produce two number (n, c) and every repeating digit will produce two “0”s on the output:
1 1 1 3 1 2 2 1 1 3 -> 3 1 0 0 0 0 1 3 1 1 2 2 0 0 2 1 0 0 1 3
[<Kernel; ReflectedDefinition>]
let lookAndSayKernel (arr : deviceptr<int8>) (len : int) (out : deviceptr<int8>) =
let ind = blockIdx.x * blockDim.x + threadIdx.x
if ind < len then
let c = arr.[ind]
let idxOut = 2 * ind
if ind = 0 || arr.[ind - 1] <> c then
let mutable i = 1
while ind + i < len && c = arr.[ind + i] do
i <- i + 1
out.[idxOut] <- int8 i
out.[idxOut + 1] <- c
else
out.[idxOut] <- 0y
out.[idxOut + 1] <- 0y
In the naive approach we bring the resulting sequence into the memory and repeat:
let lookAndSayGpu (s : string) n =
let arr = s |> Seq.map (fun c -> (string>>int8) c) |> Seq.toArray
let rec loop (arr : int8 []) n =
if n = 0 then arr.Length
else
let blockSize = 512
let gridSize = divup arr.Length blockSize
let lp = LaunchParam(gridSize, blockSize)
use dArr = worker.Malloc(arr)
use dOut = worker.Malloc(arr.Length * 2)
worker.Launch <@lookAndSayKernel@> lp dArr.Ptr arr.Length dOut.Ptr
let out = dOut.Gather()
let arr =
out
|> Array.filter (fun b -> b > 0y)
loop arr (n - 1)
loop arr n
This is almost not worth checking against the high performing imperative algorithm of the last post, but why not?
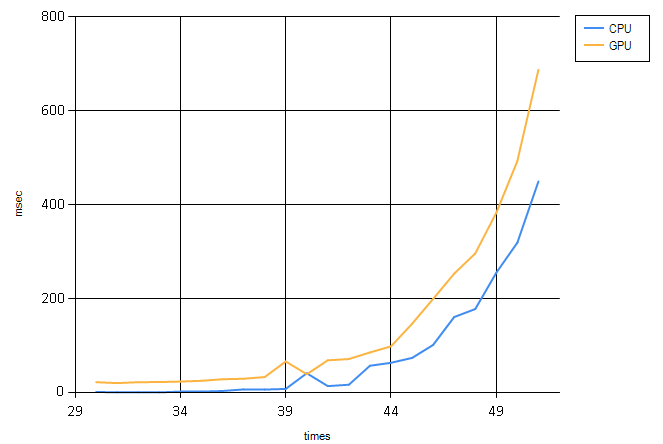
Not unexpectedly we are still falling short of the imperative solution. Not a problem. There are a few very low hanging fruit here that are just waiting to be picked.
A Better Solution
The complete script for this is on GitHub.
There are two problems with our solution so far:
- Two much memory being moved between the GPU and RAM
- A significant part of the algorithm is executed on the CPU with memory allocated and destroyed in the process (that would be the array compacting part)
The following algorithm addresses both problems:
GenerateSequences(str, n) {
//Allocate the maximum amount of memory for all data structures used on the GPU
len = str.Length
initializeGpuMemory(str, len)
for i = 1 to n {
lookAndSayKernel(len)
compactResultStream(2 * len)
len = getNewLength()
}
}
Of the 3 steps in this iterative loop, there is only one where in the implementation we move data from the GPU. It would be easy enough to not do it if necessary, though.
At the core of this algorithm there is a stream compaction routine that is executed hopefully entirely on the GPU. Compaction is performed by copying only the values needed to the addresses in the output stream. These addresses are determined by running an inclusive scan on the array of integers that contains “1” in a meaningful position, and “0” in all the rest. The details of how scan is used for stream compaction and how scans are implemented on the GPU, are discussed in GPU Gems 3 (free from NVIDIA). I’m using a device scan that comes with Alea.CUDA, which, hopefully, minimizes memory copies between main memory and GPU.
Now that the stream has been compacted, we get the length of the new sequence as the last entry in the address map, obtained during compaction (and explained in the linked chapter of GPU Gems 3).
[<Kernel; ReflectedDefinition>]
let lookAndSayKernelSimple (arr : deviceptr<int>) (len : int) (out : deviceptr<int>) (flags : deviceptr<int>)=
let ind = blockIdx.x * blockDim.x + threadIdx.x
if ind < len then
let c = arr.[ind]
let idxOut = 2 * ind
let prevUnrepeated = if ind = 0 || arr.[ind - 1] <> c then 1 else 0
flags.[idxOut] <- prevUnrepeated
flags.[idxOut + 1] <- prevUnrepeated
if prevUnrepeated = 1 then
let mutable i = 1
while ind + i < len && c = arr.[ind + i] do
i <- i + 1
out.[idxOut] <- i
out.[idxOut + 1] <- c
else
out.[idxOut] <- 0
out.[idxOut + 1] <- 0
[<Kernel; ReflectedDefinition>]
let copyScanned (arr : deviceptr<int>) (out : deviceptr<int>) (len : int) (flags : deviceptr<int>) (addrmap : deviceptr<int>) =
let ind = blockIdx.x * blockDim.x + threadIdx.x
if ind < len && flags.[ind] > 0 then out.[addrmap.[ind] - 1] <- arr.[ind]
In the modified kernel, we also fill out the “flags” array which are scanned to obtain the address map for compacting the stream. The second kernel uses the result of the scan performed on these “flags” to produce the new compacted sequence. So for the above example:
original: 1 1 1 3 1 2 2 1 1 3
new: 3 1 0 0 0 0 1 3 1 1 2 2 0 0 2 1 0 0 1 3
flags: 1 1 0 0 0 0 1 1 1 1 1 1 0 0 1 1 0 0 1 1
map: 1 2 2 2 2 2 3 4 5 6 7 8 8 8 9 10 10 10 11 12 (inclusive scan of the flags)
The last entry in the map is also the new length.
let lookAndSayGpuScan (s : string) n =
let maxLen = 20 * 1024 * 1024
let arr = s |> Seq.map (fun c -> (string>>int) c) |> Seq.toArray
use dOut = worker.Malloc(maxLen)
use dFlags = worker.Malloc(maxLen)
use dAddressMap = worker.Malloc(maxLen)
use dArr = worker.Malloc(maxLen)
dArr.Scatter(arr)
use scanModule = new DeviceScanModule<int>(GPUModuleTarget.Worker(worker), <@ (+) @>)
scanModule.Create(100) |> ignore
let sw = Stopwatch()
let rec loop n len =
if n = 0 then len
else
let blockSize = 512
let gridSize = divup len blockSize
let lp = LaunchParam(gridSize, blockSize)
use scan = scanModule.Create(2 * len)
worker.Launch <@lookAndSayKernelSimple@> lp dArr.Ptr len dOut.Ptr dFlags.Ptr
scan.InclusiveScan(dFlags.Ptr, dAddressMap.Ptr, 2 * len)
let gridSize = divup (2 * len) blockSize
let lp = LaunchParam(gridSize, blockSize)
worker.Launch <@copyScanned@> lp dOut.Ptr dArr.Ptr (2 * len) dFlags.Ptr dAddressMap.Ptr
let len = dAddressMap.GatherScalar(2 * len - 1)
loop (n - 1) len
sw.Start()
let res = loop n s.Length
sw.Stop()
res, sw.ElapsedMilliseconds
The complete code is above. Notice, that we are not cheating when we are measuring the speed of the internal loop and not including allocations. These can be factored out completely, so the only experiment that matters is what actually runs.
Here are the comparisons:
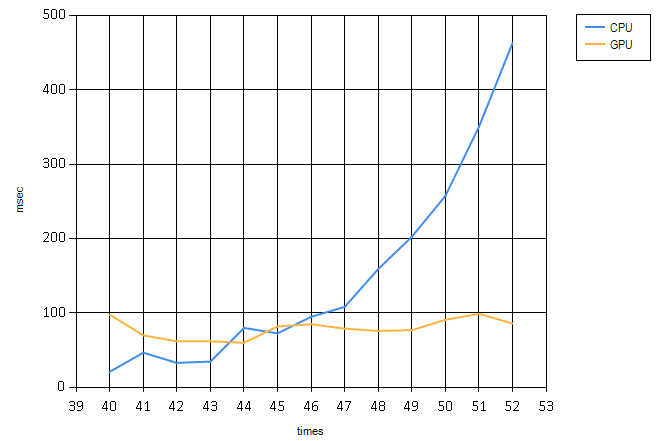
Now, we are finally fast! But it’s a mighty weird chart, probably because most of the time is spent in context switching and all other latency necessary to make this run…
So, takeaways: GPU programming makes us think differently, cool GPU algorithms exist, writing for the GPU is tough but rewarding, and we can really blow a small problem out of any proportion considered descent.
