Continuation of the previous posts:
GPU Digression
I was going to talk about something else this week but figured I’d take advantage of the free-hand format and digress a bit.
Continuing the travel metaphor and remembering Julius Cesar’s “alea iacta”, we’ll talk about GPU algorithms, for which I invariably use my favorite Aela.CUDA library.
GPU Distinct
I have already talked about sorting & splitting non-negative integer arrays on the GPU. Another one in this small library is implementing distinct on the GPU. It is using the same ubiquitous scan algorithm as before:
let distinctGpu (dArr : DeviceMemory<int>) =
use dSorted = sortGpu dArr
use dGrouped = worker.Malloc<int>(dSorted.Length)
let lp = LaunchParam(divup dSorted.Length blockSize, blockSize)
worker.Launch <@ distinctSortedNums @> lp dSorted.Ptr dSorted.Length dGrouped.Ptr
compactGpuWithKernel <@createDistinctMap @> dGrouped
- We first sort the array, so all non-distinct values get grouped together. (Using radix sort on the GPU), step complexity O(k), where k – maximum number of bits across all numbers in the array
- We then replace all values in the group except the first one with 0. One kernel invocation, so O(1) step complexity
- Compact: a variation on scan algorithm with O(log n) steps
So we have the O(log n) step and O(n) work complexity for this version of distinct. The regular linear distinct is O(n). So, is it worth it?
Here is how we test:
let mutable sample = Array.init N (fun i -> rnd.Next(0, 1000)) GpuDistinct.distinct sample
Here is the comparison:
Length: 2,097,152 CPU distinct: 00:00:00.0262776 GPU distinct: 00:00:02.9162098 Length: 26,214,400 CPU distinct: 00:00:00.5622276 GPU distinct: 00:00:03.2298218 Length: 262,144,000 CPU distinct: 00:00:03.8712437 GPU distinct: 00:00:05.7540822
Is all this complexity worth it? It’s hard to say, because as it is obvious from the above numbers, there is a lot of latency in the Alea.CUDA scan, which makes its application useful only once we have an array sufficiently large to hide this latency.
I could not do much in terms any further comparison – ran out of GPU memory before I ran out of .NET object size limitation.
The final comparison:
Length: 300,000,000 CPU distinct: 00:00:04.2019013 GPU distinct: 00:00:06.7728424
The CPU time increase ratio is 1.11, while the GPU increase was 1.18, while the increase in the size of our data is 1.14 – so not really informative: all we can see is that the work complexity is indeed O(n) in both cases, and that’s certainly nothing new. We could responsibly claim, however, that if it weren’t for the latency, our GPU implementation would be faster. Perhaps switching to C++ would confirm this statement.
Computing Graph Properties
Motivation
Remember, for the visuals, we wanted to clearly identify vertices with certain numbers of incoming/outgoing edges. Another case: implementing the spanning tree algorithm, it is necessary to “convert” the directed graph to undirected. This is not a real conversion, we would just need to make sure that if (a -> b) exists in the graph, it means that (a b), i.e. – edges are connected no matter the direction. Our spanning tree should be using “weak” connectivity:
let euler = StrGraph.GenerateEulerGraph(8, 3, path=true) euler.Visualize(spanningTree=true, washNonSpanning=false)
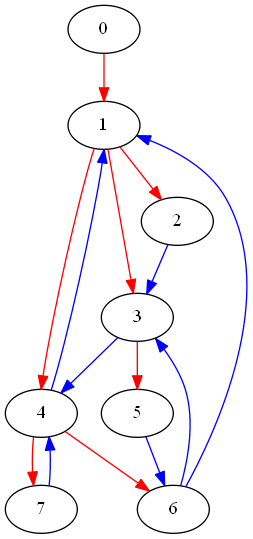
Here red edges mark the “spanning” tree, this graph is “almost” strongly connected – it has an Euler path.
Graph as an Iterable
We need an ability to iterate over the vertices of our graph. So, we should be implementing IEnumerable<DirectedGraph> to accomplish this, right? Wrong! What we want is the AsEnumerable property. Makes things clean and easy. It uses Seq.init method – which comes very handy any time we need to turn our data structure into an iterable quickly and cleanly.
member this.AsEnumerable = Seq.init nVertices
(fun n -> nameFromOrdinal n, this.[nameFromOrdinal n])
Now we can also do ourselves a favor and decorate our class with the StructuredFormatDisplay("{AsEnumerable}") to enable F# Interactive pretty printing of our graph:
[<StructuredFormatDisplay("{AsEnumerable}")>]
type DirectedGraph<'a when 'a:comparison> (rowIndex : int seq, colIndex : int seq, verticesNameToOrdinal :
Now if we just type the name of an instantiated graph in the interactive, we’ll get something like:
val it : DirectedGraph =
seq
[("0", [|"2"|]); ("1", [|"2"|]); ("2", [|"3"; "4"; "5"|]);
("3", [|"5"; "6"; "7"|]); ...]
We can further improve on what we see by calling
gr.AsEnumerable |> Seq.toArray
to completely actualize the sequence and see the textual representation of the entire graph.
“Reverse” Graph
So, if we want all the above goodies (number of in/out edges per vertex, spanning tree), we need to extract the array of actual edges, as well as be able to compute the “reverse” graph. The “reverse” graph is defined as follows:
Given 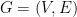

That is for every edge of the original graph, the edges of the new one are created by reversing the original edges’ direction. In order to reverse the edges direction we must first obtain the edges themselves. If an edge is represented as a tuple 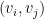
This can get time-consuming, that’s why we use F# lazy values to only invoke the computation once, when we actually need it:
let reverse =
lazy (
let allExistingRows = [0..rowIndex.Length - 1]
let subSeq =
if hasCuda.Force() && rowIndex.Length >= gpuThresh then //use CUDA to reverse
let start, end' =
let dStart, dEnd = getEdgesGpu rowIndex colIndex
sortStartEnd dStart dEnd
Seq.zip end' start
else
asOrdinalsEnumerable ()
|> Seq.map (fun (i, verts) -> verts |> Seq.map (fun v -> (v, i)))
|> Seq.collect id
let grSeq =
subSeq
|> Seq.groupBy fst
|> Seq.map (fun (key, sq) -> key, sq |> Seq.map snd |> Seq.toArray)
let allRows : seq<int * int []> =
allExistingRows.Except (grSeq |> Seq.map fst) |> Seq.map (fun e -> e, [||])
|> fun col -> col.Union grSeq
|> Seq.sortBy fst
let revRowIndex = allRows |> Seq.scan (fun st (key, v) -> st + v.Length) 0 |> Seq.take rowIndex.Length
let revColIndex = allRows |> Seq.collect snd
DirectedGraph(revRowIndex, revColIndex, verticesNameToOrdinal)
)
member this.Reverse = reverse.Force()
On line 35, .Force() will only call the computation once and cache the result. Each subsequent call to .Force() will retrieve the cached value.
It’s worth mentioning what code on line 24 is doing. By now we have the array of all “terminal” vertices, which will become the new “outgoing” ones. However if the original graph had vertices with nothing going into them, they will have nothing going out of them in the current graph, and thus the new “reversed” grSeq will be incomplete. We need to add another vertex with 0 outgoing edges:
let s = [|"a -> b, c, d, e"|]; let gr = StrGraph.FromStrings s gr.Visualize() gr.Reverse.Visualize()
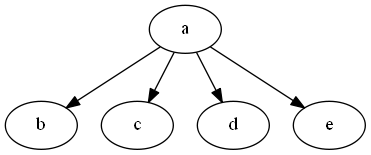
|
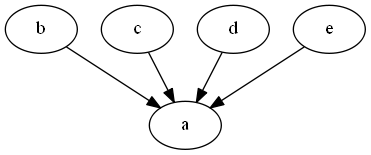
|
Reversing on the GPU
The code above makes use of the GPU when it detects that the GPU is present and the graph is sufficiently large to warrant the GPU involvement. Right now, I am setting the threshold to 
I am only making this decision for generating the edges array, which is created on the GPU as two arrays: start and end' that hold the edge nodes. Further, this tuple of arrays in converted into the array of tuples – a data structure more suited for representing an edge.
It is possible to delegate more to the GPU if we know for sure we are not going to get into the situation handled on line 24 above. And we won’t, if we are dealing with Euler graphs. For now, let’s compare performance of just finding the edges part. The step complexity for the GPU implementation is O(1), this is a pleasantly parallel task, so things are easy.
[<Kernel;ReflectedDefinition>]
let toEdgesKernel (rowIndex : deviceptr<int>) len (colIndex : deviceptr<int>) (start : deviceptr<int>) (end' : deviceptr<int>) =
let idx = blockIdx.x * blockDim.x + threadIdx.x
if idx < len - 1 then
for vertex = rowIndex.[idx] to rowIndex.[idx + 1] - 1 do
start.[vertex] <- idx
end'.[vertex] <- colIndex.[vertex]
Here is the test:
let mutable N = 10 * 1024 * 1024
let k = 5
sw.Restart()
let gr = StrGraph.GenerateEulerGraph(N, k)
sw.Stop()
printfn "Graph: %s vertices, %s edges generated in %A"
(String.Format("{0:N0}", gr.NumVertices)) (String.Format("{0:N0}", gr.NumEdges)) sw.Elapsed
sw.Restart()
let starts, ends = getEdges gr.RowIndex gr.ColIndex
sw.Stop()
printfn "GPU edges: %A" sw.Elapsed
sw.Restart()
gr.OrdinalEdges
sw.Stop()
printfn "CPU edges: %A" sw.Elapsed
And the output:
Graph: 10,485,760 vertices, 31,458,372 edges generated in 00:00:18.9789697 GPU edges: 00:00:01.5234606 CPU edges: 00:00:16.5161326
Finally. I’m happy to take the win!
