In the following series I will explore different tools and techniques for doing object detection in streaming video in real time or faster. Starting with the baseline Python detector running slowly and gradually picking up speed.
In these series
In the course of these posts we will explore optimizing object detection in videos. We will use an SSD detector and trace its evolution from the baseline performance of ~19 fps to the vertiginous 200 fps. We will need a powerful GPU for this: the one I benchmarked was Titan V, but any other powerful CUDA-enabled device will do. Here is the sequence of the posts:
- Introduction: Baseline
- Setup – how to build everything we need for these experiments
- First App – first optimization results
- Optimizing Decoding and Graph Feeding – address video decoding and network setup issues to extract performance gains
- TensorRT 5 Achieving our turbo goals with NVIDIA TensorRT framework.
Baseline
Suppose you are streaming a video to your local machine with a Volta GPU (mine is Titan V if I’m doing it at home or a V-100 if I’m grabbing an Azure VM). You picked Tensorflow as your framework and you have trained an object detector, let’s say an Inception V2 SSD with transfer learning, or even forget training. You are using a stock COCO dataset trained Inception V2 SSD detector.
The result you want is something like the video above, where the objects are detected and marked in real time. If you google Python code for it, you will end up with something like this:
class TfOD:
'''
Detectors
'''
pred_keys = ['num_detections', 'detection_boxes', 'detection_scores', 'detection_classes', 'detection_masks']
def __init__(self, detpath=None, labelpath=None):
self.detpath = detpath
self.labelpath = labelpath
if self.detpath is not None:
self.load_model()
if self.labelpath is not None:
self.get_categories()
self.sess = tf.InteractiveSession(graph=self.G)
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
if self.sess is not None:
self.sess.close()
def load_model(self):
self.G = tf.Graph()
with self.G.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(self.detpath, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
def get_categories(self, NUM_CLASSES=90):
label_map = label_map_util.load_labelmap(self.labelpath)
categories = label_map_util.convert_label_map_to_categories(
label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
self.categories = categories
def detect(self, images, threshold=0.8, denormalize_coordinates=True):
'''
Detection generator
Parameters:
images: list of numpy arrays representing (height, width, 3) images
threshold: detection threshold
denormalize_coordinages: should coordinates be converted from absolute to relative to image dimensions
Returns:
iterable of dictionaries of pred_keys detections (per image)
'''
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {
output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in self.pred_keys:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(tensor_name)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
for i, image in enumerate(images):
ts = perf_counter()
tfpred = self.sess.run(tensor_dict, feed_dict={image_tensor: np.expand_dims(image, 0)})
te = perf_counter()
# extract actual predictions
tfpred = {k : v[0] for k, v in six.iteritems(tfpred)}
tfpred['detection_classes'] = tfpred['detection_classes'].astype(np.int32)
# threshold
thresh = tfpred['detection_scores'] >= threshold
tfpred = {k: v[thresh] for k, v in six.iteritems(tfpred) if k != 'num_detections' and k != 'time'}
tfpred['num_detections'] = len(np.nonzero(thresh)[0])
if denormalize_coordinates:
width = image.shape[1]
height = image.shape[0]
detections_boxes = []
for r in tfpred['detection_boxes']:
y1, x1, y2, x2 = r
detections_boxes.append([int(y1 * height), int(x1 * width), int(y2 * height), int(x2 * width)])
tfpred['detection_boxes'] = np.array(detections_boxes)
tfpred['time'] = te - ts
yield tfpred
You can instantiate it and run detect() on every frame of your video. The frames will be extracted using OpenCV
<br>
cap = cv2.VideoCapture(video_path)<br>
nFrame = 30<br>
iFrame = 0<br>
start = time.time()</p>
<p>pred_ims = []</p>
<p>with TfOD(frozen_graph_path, label_file_path) as detector:<br>
while iFrame < 500:<br>
ret, frame = cap.read()<br>
if not ret:<br>
break</p>
<p> iFrame += 1</p>
<p> if iFrame % nFrame == 0:<br>
end = time.time()<br>
total = float(end - start)<br>
fps = float(nFrame) / total<br>
print("fps: {:.2f}".format(fps))<br>
start = time.time()</p>
<p> threshold = 0.1<br>
# we really suck with the current model...<br>
for i, (pred, im) in enumerate(zip(detector.detect([frame], threshold=threshold), [frame])):<br>
rects = pred['detection_boxes']<br>
scores = pred['detection_scores']<br>
classes = pred['detection_classes']</p>
<p> if len(rects) > 0:<br>
rects, scores = non_max_suppression_with_tf(detector.sess, rects, scores, 5, threshold)<br>
rects = np.array(rects)<br>
if True:<br>
img = vis_utils.visualize_boxes_and_labels_on_image_array(<br>
im,<br>
rects, classes, scores, category_index,<br>
instance_masks=None, use_normalized_coordinates=False, line_thickness=8, min_score_thresh=threshold<br>
)<br>
pred_ims.append(img)<br>
cap.release()<br>
Then you launch it on a 720 HD video stream running at 30 fps (frames per second) and performance you get is:
fps: 8.24 fps: 22.16 fps: 22.28 fps: 20.58 fps: 20.63 fps: 19.28 fps: 19.74 fps: 18.91 fps: 18.93 fps: 19.08 fps: 19.01 fps: 18.91 fps: 16.68 fps: 17.71 fps: 17.55 fps: 17.51
(From my Jupyter Notebook, collecting data every 30 frames). Notice that I’m clocking:
- Decoding and reading a video frame
- Running the object detector on it.
All the auxiliary stuff (in this case – collecting individual frames with detection results drawn on them) is not included in the timing.
Ok, not quite glacial, more than half way there, we have 18.75 fps on average performance.
Let’s look at one of the frame grabs:
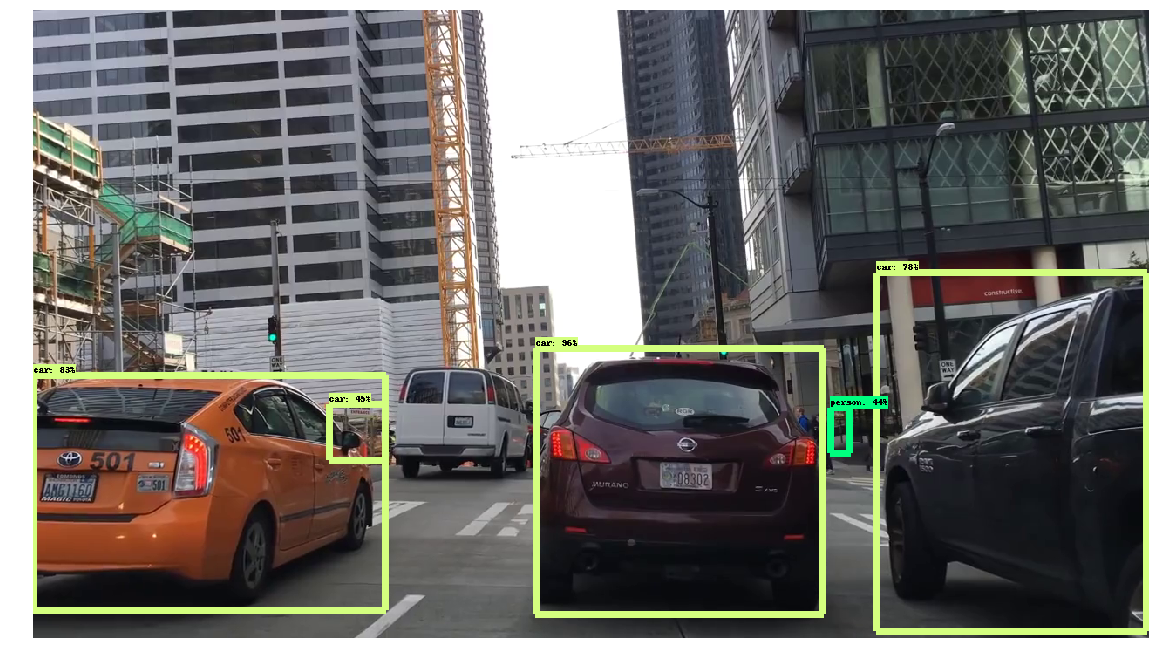
So we are doing the right thing.
Gearing up
In the course of these posts we will achieve an order of a magnitude performance increase on a single stream coming into a single GPU without sacrificing accuracy (too much).
We can then take this project to the next level with NVIDIA DeepStream and edge devices where up to 30 streams can be piped into a single GPU and still keep the real time detection performance on each stream.
The purpose of this is learning, observing, touching things with our own hands, so let’s get technical!
