In the previous post we validated our install and ran a simple detector in C++. It is now time to start optimizing it. Source code for the finished project is here.
Optimizing Video Decoding
If we build and run the video_reader.cpp OpenCV sample, we will observe a staggering performance improvement available in OpenCV for decoding and reading video.

It is somewhat tricky to make the actual sample work, so I summarized the necessary steps gleaned from some wise folks on GitHub Issues in this repo.
As the screenshot above shows, we have an order of magnitude performance improvement by decoding the video and leaving frames on the GPU. At this point this is our performance increase potential: not only will it allow us to skip unnecessary and expensive memory copies, but also will set the stage for TensorRT which consumes data already on the GPU.
The first step towards this goal is to optimize feeding the Tensorflow graph.
Feeding Tensorflow Graph from the GPU
We are now working with the final version of this application from this repo. The first thing to do is to allocate a GPU tensor and fill it with decoded data, which, at this point, is also residing on the GPU in a GpuMat structure. Let’s deal with this copy first. Here we are just as lucky as we were with bridging Mat with Tensorflow tensors.
Status readTensorFromGpuMat(const cv::cuda::GpuMat& g_mat, Tensor& outTensor) {
tensorflow::uint8 *p = outTensor.flat().data();
cv::cuda::GpuMat fakeMat(g_mat.rows, g_mat.cols, CV_8UC3, p);
// comes in with 4 channels -> 3 channels
cv::cuda::cvtColor(g_mat, fakeMat, COLOR_BGRA2RGB);
return Status::OK();
}
A noteworthy bit here is on line 6: the decoded frame has 4 channels, we use cvtColor to drop the transparency channel our network does not use.
Allocating CUDA Tensor
By carefully studying Tensorflow code:
// GPU allocator
#include "tensorflow/core/common_runtime/gpu/gpu_id.h"
#include "tensorflow/core/common_runtime/gpu/gpu_id_utils.h"
#include "tensorflow/core/common_runtime/gpu/gpu_init.h"
#include "tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.h"
const string gpu_device_name = GPUDeviceName(session.get());
// allocate tensor on the GPU
tensorflow::TensorShape shape = tensorflow::TensorShape({1, height, width, 3});
tensorflow::PlatformGpuId platform_gpu_id(0);
tensorflow::GPUMemAllocator *sub_allocator =
new tensorflow::GPUMemAllocator(
tensorflow::GpuIdUtil::ExecutorForPlatformGpuId(platform_gpu_id).ValueOrDie(),
platform_gpu_id, false /*use_unified_memory*/, {}, {});
tensorflow::GPUBFCAllocator *allocator =
new tensorflow::GPUBFCAllocator(sub_allocator, shape.num_elements() * sizeof(tensorflow::uint8), "GPU_0_bfc");
inputTensor = Tensor(allocator, tensorflow::DT_UINT8, shape);
To confirm the tensor is indeed residing on the GPU:
bool IsCUDATensor(const Tensor &t)
{
cudaPointerAttributes attributes;
cudaError_t err =
cudaPointerGetAttributes(&attributes, t.tensor_data().data());
if (err == cudaErrorInvalidValue)
return false;
CHECK_EQ(cudaSuccess, err) << cudaGetErrorString(err);
#if CUDART_VERSION >= 10000
return (attributes.type == cudaMemoryTypeDevice);
#else
return (attributes.memoryType == cudaMemoryTypeDevice);
#endif
}
CUDA 10 is depricating memoryType attribute, so the conditional compilation avoids compiler warnings.
Feeding Tensorflow Graph from the GPU
Doing this is not standard. See a long discussion on GitHub.
There exists an experimental technology, so things will probably change, but as of release 1.12 it still works. This is a sample from Google.
In our case this works:
CallableOptions opts;
std::unique_ptr<tensorflow::Session> session;
Session::CallableHandle feed_gpu_fetch_cpu;
const string inputLayer = "image_tensor:0";
const vector<string> outputLayer = {"detection_boxes:0", "detection_scores:0", "detection_classes:0", "num_detections:0"};
opts.add_feed(inputLayer);
for (auto const &value : outputLayer)
{
opts.add_fetch(value);
}
const string gpu_device_name = GPUDeviceName(session.get());
opts.clear_fetch_devices();
opts.mutable_feed_devices()->insert({inputLayer, gpu_device_name});
auto runStatus = session->MakeCallable(opts, &feed_gpu_fetch_cpu);
if (!runStatus.ok())
{
LOG(ERROR) << "Failed to make callable";
}
runStatus = session->RunCallable(feed_gpu_fetch_cpu, {inputTensor}, &outputs, nullptr);
....
We can compare the results by looking at NVIDIA Profiler results for our previous app and the current one:
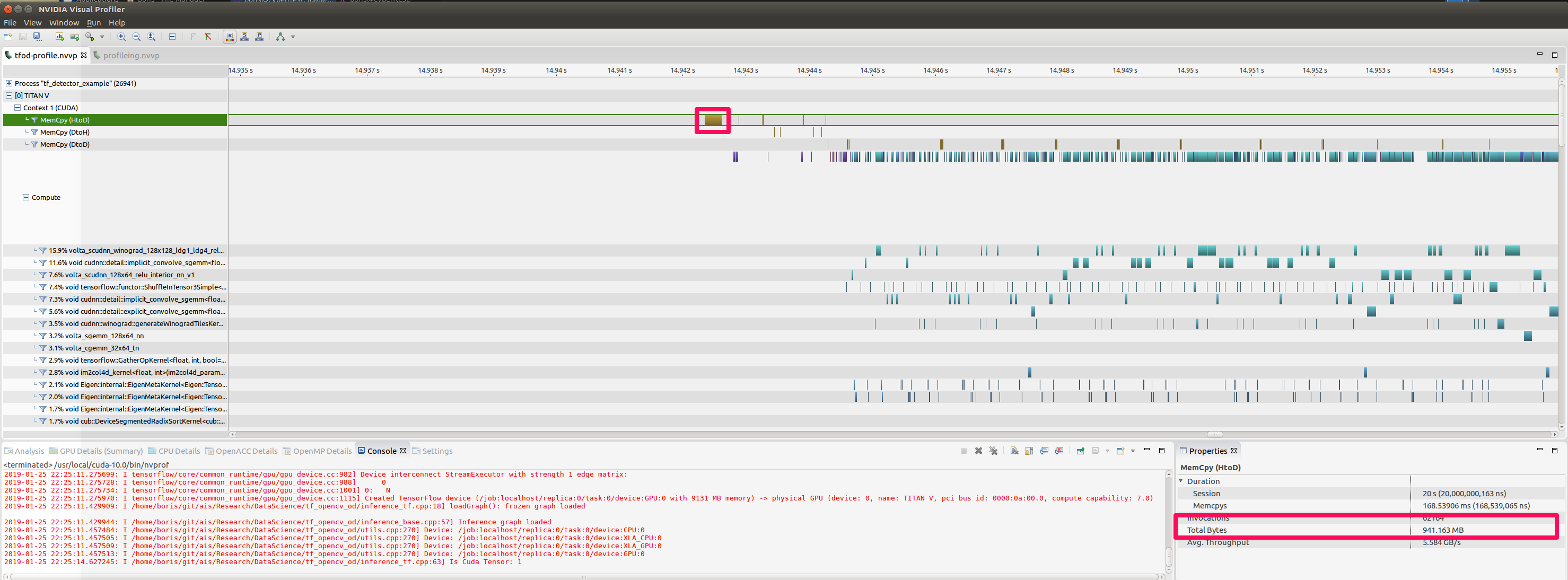
Feeding from the CPU
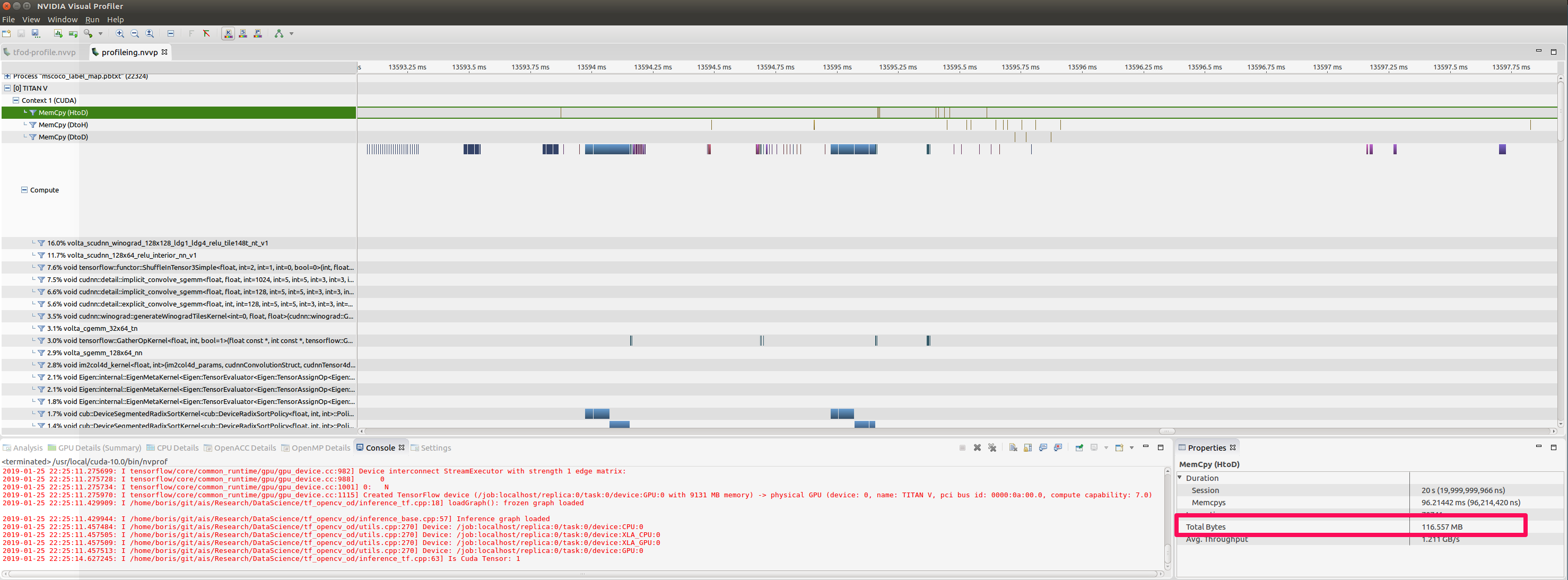
Feeding from the GPU
(See the regions framed in deep pink on images above, marking large chunks of memory moved from host to device in the top snapshot)
Profile was taken over 20 seconds and we can see the difference in bytes moved back and forth. Also we can see individual bursts of 2.76 Mb moved from host to device on the “CPU” profile that do not appear on the “GPU”. It is easy enough to calculate that 2.76 Mb is the size of a decoded frame.
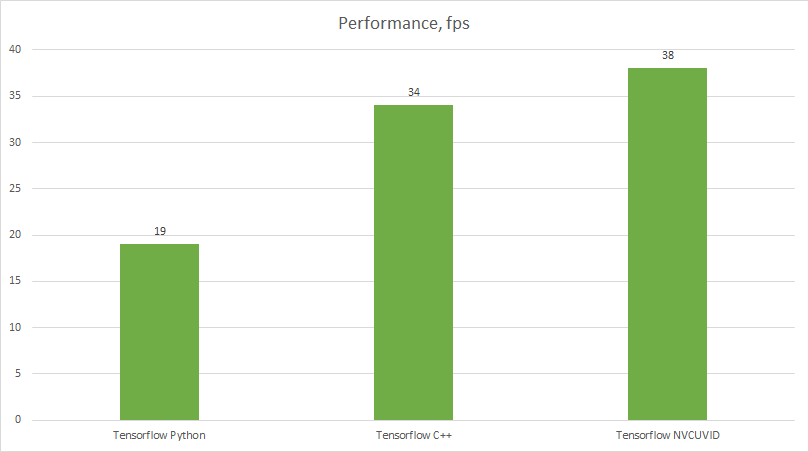
Performance Gain
So, how much did we gain through all this? A whopping 10%. We did expect more for all this work, however we will use what we learned to enable bigger gains down the line. It is now time to move to TensorRT.

One thought on “Supercharging Object Detection in Video: Optimizing Decoding and Graph Feeding”